枯山水 - Karesansui: The Garden
⊕ Continuous
I’ve always commented to other security people that I treat my network as a rock garden, something that I curate and make just the way I want it to flow void of the things that plague me on my hacking excursions. Enough people have asked me about it that I decided to actually show it and use this documentation as my continuous documentation efforts. I plan on updating this over time as I change things and add components. This is partially my own documentation and to share the fun of self-hosting.
Additionally, there is a portion of this that is more me waxing about design principles than anything else, that starts at the zen. There is nothing technically useful in this components, just some thoughts about my process for self-hosting.
The very high level view of my network can be seen below. Red indicates its accessible directly from a wireless or internet connection, green indicates that it’s a physical hardware device, and gray generally means virtualized:
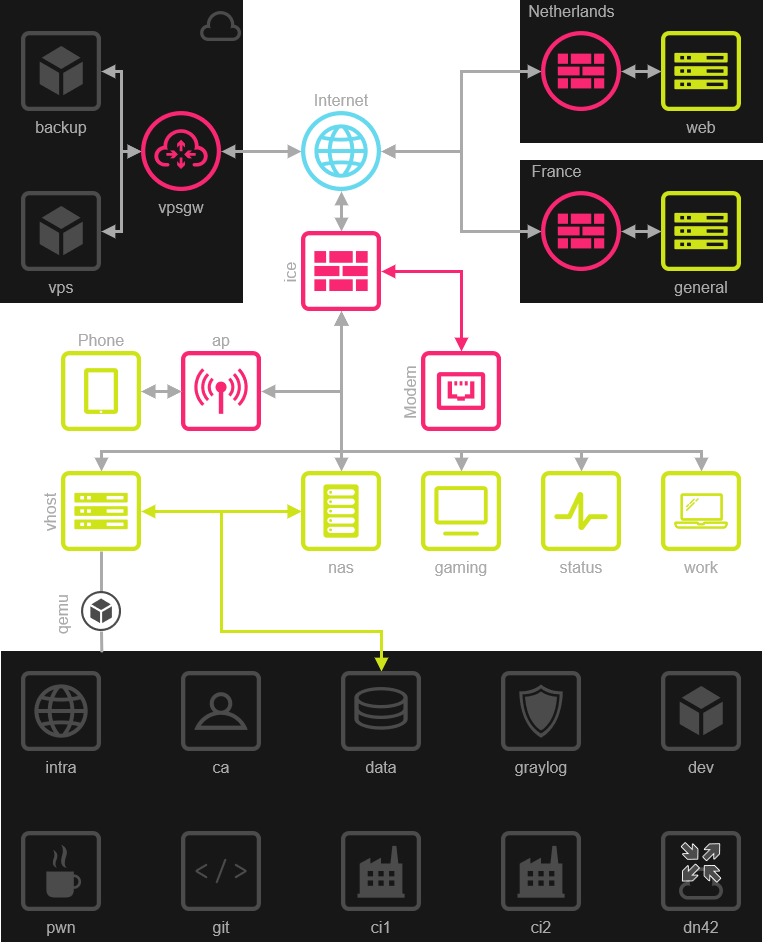
System Index
Network
Services & Hosts
- Intra
- Git
- Continuous Integration
- Miniflux RSS
- Logs
- Status & Notifications
- Notes & Stagnant
- NAS & Backups
- Archiving
- Virtual Host
- Router & DNS
- Wireless Access Point
- ISP Modem
- Workstation
- Cloud Systems & International Hosts
- Misc. Devices
Design Principles
Operating Systems
In the network all network devices use the following set of operating systems, in order of personal preference:
- OpenBSD - 15 devices
- HardenedBSD - 1 device
- Void Linux - 5 devices (musl & glibc)
- OpenWRT - 1 device
- Windows - 1 device
- Misc - 3 devices
The vast majority of the hosts and VMs in the network are OpenBSD, but certain systems or dependencies require me to have a Linux or FreeBSD operating system for features like ZFS or a QEMU virtualization platform.
High Level Hardware
| Name | Device | Hardware |
|---|---|---|
| nas | Network Storage | 2x Intel Xeon X5687 4 core, 48G ECC, 19T over 8 disks |
| vhost | Virtual Host | 2x Intel Xeon E5649 12 core, 48G ECC, 2 T over 2 disks |
| ap | Wireless AP | TP-Link N900 |
| status | Status / Monitoring | Zotac CI320 Nano |
| ca | Certificate Authority | USB Armory MKII |
| work | Work Machine | REDACTED |
| dev | Dev Machine | Lenovo X240 |
| game | Cracking & Gaming | Intel i7-6700K, 48G, 4T over 2 disks, Nvidia GTX 2070 Super |
| ice | Router | PCEngines apu4d4 |
| modem | Terrible modem | Trash AT&T Modem… Trying to kill |
Network
One of the key components of structuring my network was to assume that everything that was not behind a WireGuard network address was untrusted, including devices and networks in my ecosystem. There is a habit of creating strong perimeter layers, and it’s a bit of a misnomer to actually structure networks in that way, instead I try and build them with the intent of not trusting anyone, including other nodes. Generally this means host-based firewall rules, local authentication handling that doesn’t rely on external signatures (SAML, OAUTH, etc) and purposefully create central audit and authentication endpoints.
In general, I believe it’s best to assume that layer 2 is not your friend and broadcast protocols are trying to eat you. I also attempt to put firewall rules on my layer 2 traffic and isolate my hosts as much as possible with an attempt at following default deny and least privilege.
WireGuard
WireGuard is at the core of my network design, I’ve written about WireGuard extensively since before an userspace module existed and I really believe that it is some of the highest quality designed network protocols and gives me some really feelings to when the first time I read the design of djb’s CurveCP.
I have a couple of “central” endpoints that I used to increase speed and decrease hops on local links or prevent having to route over the internet. My router, ice, is the central connection point for all devices, but my virtual host and my EU endpoints have their own central route.
I’m using the in-kernel deployment for all hosts except the HardenedBSD endpoint, which due to lack of in-kernel option uses the Go package. The actual /etc/hostname.wg0 looks roughly like this partial snippet:
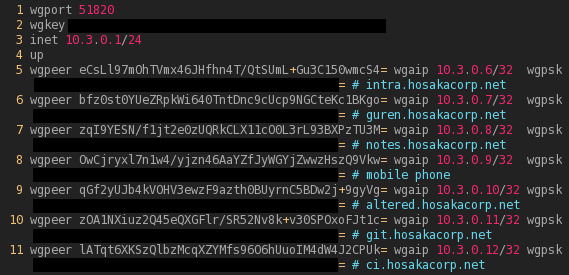
Management is currently manual and requires me to generate keys and deploy them by hand to new devices. I do have plans and a side project of creating an automated PKI enrollment system that is described in this articles mana section.
SSH Certificates
SSH key management is always a pain and I think there are a couple of core design pain points that I’ve run into from a security and attacker perspective that I wanted to deal with. The core issues for me are:
- User controlled authorization - I think the default behavior of having keys be available in a user controlled
~/.ssh/authorized_keysfile is extremely handy but opens up to attackers with write access on services running as interactive users to gain access to SSH servers, something I do very often on penetration tests. - Knowledge of key material before authorization - The TOFU behavior of SSH requires you and the server to both be aware of each other to have a fully secure by first connection tunnel. Pragmatically TOFU is awesome and is a very approachable way to not have to deal with a full PKI, but once you want a bit more and not have to throw around or sync
known_hostsfiles (or DNS based ones) things can get unruly.
To solve this problem I highly suggest using the OpenSSH certificate format, I have laid this out in much more detail about how I use this for all aspects of my network in this blog post.
Essentially I keep a list of signed users, hosts, roles, and other identifying metadata for each key. This allows me to have a fairly robust model for deploying new keys and a much easier time adding new authorizations to hosts. For example, if I deploy a new git server to use a post hook to push to CI after a commit is merged all I have to do is add git to the /etc/ssh/authorized_principles/ci and then using the config declaration AuthorizedPrincipalsFile /etc/ssh/authorized_principals/%u and the PKI I am good to go, no prior knowledge of keys and no more fighting authorized keys files for tons of hosts.
This also massively increases the ease of auditability on my SSH key authentications. I have even used this technique to leak SSH “honey keys” that if hit my network will send me an emergency alert.
Currently, I have a couple of scripts to manage each of these components, but things are manual, but is a component of my mana project.
TLS Certificates
TLS certificates are also deployed in my network using an internal only certificate authority using a local host only cfssl deployment. Automating of CSRs is much easier using cfssl is actually pretty reasonable to handle requests in a scripted manner.
An annoyance I have run into is that I have attempted to use ed25519 as my root and signature for all cryptosystems, but Android cannot handle those server signatures and I have had to move to signing with ECDSA with SHA-384 as a sad substitute.
Services
Now that the basic network layer and tunnel requirements are a bit more clear I think it’s worth talking about which services are exposed over the secure endpoints, each of which are built with those protections in place. A closer look at the host layout can be seen in the following network diagram:
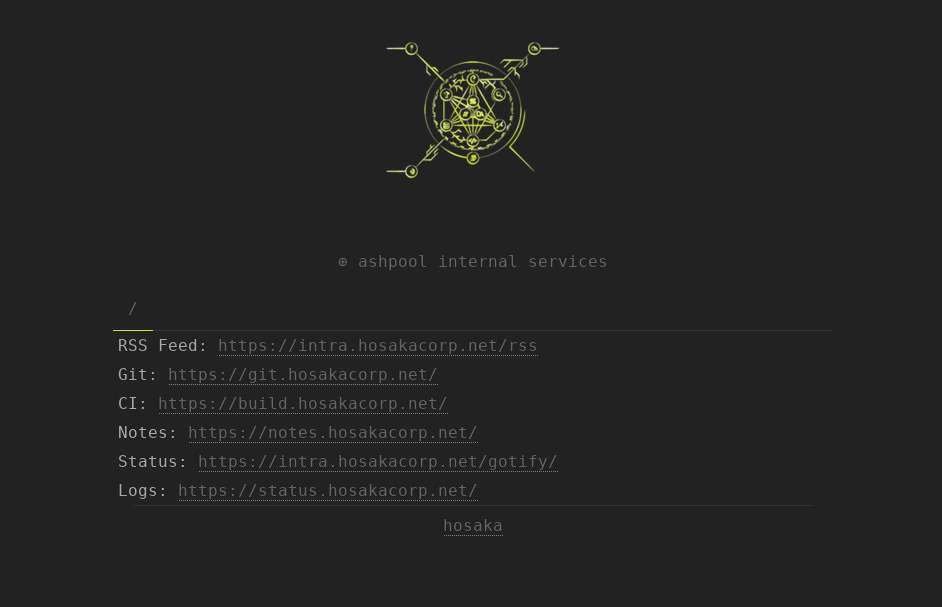
Intra
- Host:
home.hosakacorp.net - OS: OpenBSD - Virtualized
One host on my network that acts as a “central” hub that I used to have a simple landing page (because I also can’t remember all this) and as a central place to retrieve system wide files, changes, and blobs. When I push out a new KRL or a new file that I need on all my hosts, this is the central host that they are retrieved from. I attempt to use signify(1) to sign all the documents that are hosted here, but some are also considered to be “non-sensitive” and also behind WireGuard.
Git
- Host:
git.hosakacorp.net - OS: OpenBSD - Virtualized
One of the most important hosted services in my network is my local git server, I attempt to programmatically build services from code, snippets, or automation. In fact this blog and website are all generated from markdown using stagnant. Following my principle of “static first” I host the git server over a flat file deployment over SSH and then generate static host content that is deployed using stagit.
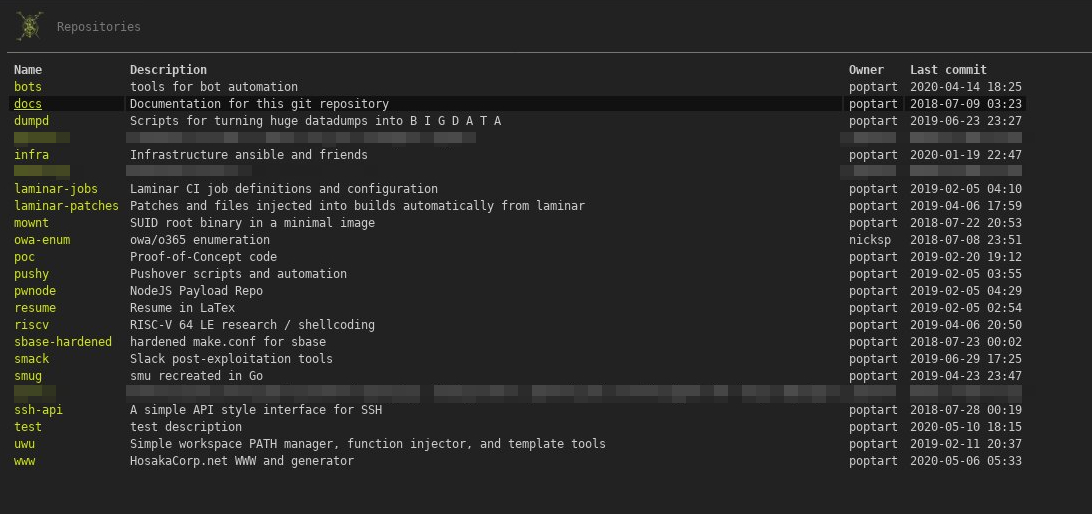
Each repo is generally integrated into the CI environment or requires manual triggering.
Continuous Integration
- Host:
ci.hosakacorp.net - OS: Void Linux - Virtualized
CI is used pretty globally in the network and my general philosophy of making everything blobs or code makes it very easy to integrate infrastructure, code, and backups into the CI. CI is often a massively overly complex piece of software that requires specific tooling knowledge or CI workflows that just don’t make sense in my environment (Docker isn’t allowed here). In order to embrace the ideal of “in the end it’s all syscalls and shell scripts” I identified Laminar as my CI platform of choice, and it’s been a great experience. Write shell scripts, integrate them into the laminar jobs repo, and use hooks to push new jobs and run laminar builds. Simple. No DSL, no groovy, no authentication, no interactivity besides manual triggers and commits, and easily replicateable for runners.
Currently, I have a glibc and musl build secondary, which in Laminar terms really just means my main CI host has an SSH key to access the other secondary. All very simple and honestly easy to scale if I needed to.
Miniflux RSS
- Host:
feed.hosakacorp.net - OS: OpenBSD - Virtualized
I am easily distract and am one of those people who have about a hundred projects at once. I recognized this long ago and started maintaining all of my news and information that I consume into a single feed, if there was one thing that “fixed the web” for me, it was setting up an RSS feed. RSS feeds let me easily follow people without accounts, without fighting some sort of algorithm, and allows me to have a single place I can go. That cup of coffee and lunch where I can just go to the feed and have a single place of distraction helps me focus a lot.
Miniflux was also hands down the best choice for me, for the longest time I was reading over newsbeuter over terminal and I liked that. But since I’ve been mixing my workflows between terminals, different machines, and having a way to reach my news aggregation from my phone I needed an intermediary. Miniflux is also very minimal and easy to customize (just look at that theme!).
Logs
- Host:
status.hosakacorp.net/logs.hosakacorp.net/graylog.hosakacorp.net - OS: OpenBSD - Physical
All systems in my network that can use syslog ingestion and I aggregate that into a Graylog instance running on OpenBSD. This instance is actually dual virtual hosted and the status page that ingests my web logs from all my instances aggregates and outputs via GoAccess so that I can monitor things and avoid using third party analytics. Additionally, a note should be thrown out that my Windows devices use NXLog in order to turn Windows log streams into syslog and all the syslog instances as usual are only exposed over WireGuard.
My Graylog server is used to track all instance logins and all access as well as creating dynamic firewall rules and tracking central open source threat lists.
I decided to set this up as an independent host so that I could keep my logs aggregated even if the main virtual hosts or critical systems were down.
This host also acts as my uptime status and heartbeat server. In order to keep the uptime checks and check-ins in place it is placed in a 1U server with other IoT devices and is connected to a little display that shows which devices are up. This is done using a wrapper around dwm and surf pointing to a local HTML file that gets updated through Go HTML templates. More info on this as soon as I can flesh out presence detection stuff and power scaling using this host.
Status & Notifications
- Host:
notify.hosakacorp.net - OS: OpenBSD - Virtualized
I’m a big fan of pragmatic security, you don’t always need AI next-gen firewalls to help you, sometimes security gains can also be simple. One way I have integrated security is by combining my syslog logs to simple notifications to my phone and desktops using gotify. I notify on all authentications, ssh logins, new hosts in my network from the gateway, and a few more examples from enriched data. Pretty simply I just feed syslog triggers from Graylog to call the Gotify API.
Additionally, I also use the notification for simple reminders. I will often send Gotify a notification trigger when I need to remember to do something.
Eventually I would like to use this to also handle downscaling and reduction of power consumption, but that is a rant for a different time.
Notes & Stagnant
- Host:
notes.hosakacorp.net - OS: OpenBSD - Virtualized
Notes are fundamental to my workflow, as described in more detail in the other half this post I use markdown for everything I possibly can. Normally I write all my notes in vim with the Goyo plugin, but I’m also pragmatic and also need to edit while on the move with a phone or a device that can’t/isn’t running vim. For this I use pervane and a few git hooks to keep things synchronized.
In order to actually render the documents and make them viewable I use my handmade site build system called stagnant that uses a defined structure and fundamentally just sets a pile of environment variables and leaves everything up to basic pipelining using executables and scripts. That’s how this website is built, that’s how I keep all my notes, and that’s how I generate notes using mdbook on penetration tests. They use the same build system, just different pipeline scripts and executables.
NAS & Backups
- Host:
files.hosakacorp.net - OS: HardenedBSD - Physical
The NAS infrastructure is one of the most important systems in my network. It handles my backups, simple network storage, datasets, and stores my indexes for databases/Elasticsearch. I’m not a big fan of off the shelf products that are overly complicated and come with more pain points than they alleviate. So I decided to build two ZFS pools with the following layout:
poptart@mieli:~ $ zpool status
pool: backup
state: ONLINE
scan: scrub repaired 0 in 0 days 00:55:24 with 0 errors on Tue Feb 9 23:12:47 2021
config:
NAME STATE READ WRITE CKSUM
backup ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0 ONLINE 0 0 0
diskid/DISK-K4JT3A7B ONLINE 0 0 0
errors: No known data errors
pool: nas
state: ONLINE
scan: scrub repaired 0 in 0 days 07:39:31 with 0 errors on Wed Feb 10 05:56:47 2021
config:
NAME STATE READ WRITE CKSUM
nas ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada1 ONLINE 0 0 0
diskid/DISK-P8GSLA7R ONLINE 0 0 0
logs
nvd0 ONLINE 0 0 0
cache
nvd1 ONLINE 0 0 0
errors: No known data errors
pool: zroot
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
zroot ONLINE 0 0 0
ada2p3 ONLINE 0 0 0
errors: No known data errors
Backups are done from all hosts to this server using a couple of different configurations: zfs based and restic based. For hosts that support ZFS I use zfs send over SSH using specific OpenSSH PKI ssh backup role keys. There are multiple other hosts on my network that do not use ZFS (such as my primary use of OpenBSD) I use restic for host specific configuration backups.
I also push off-site backups to 3 different locations depending on the data I’m backing up. Critical backups for my personal documents, code, and critical files are sent up to physical hosts in the Netherlands and Backblaze B2. Remember, test access to backups in case something goes wrong!
My NFS fileshare is done using write-only over WireGuard and I attempt to hold a policy of never sending sensitive data over NFS directly. One of the primary uses I have for the NFS is for multihost access to datasets, public breach data, and gathered OSINT data streams. This configuration also is the motivation for why I implemented NVMe disks for ZFS cache and log in order to speed up access. I think that the log and cache features are some of the coolest and most useful things in my deployment, and it has made my disk costs far less.
There are a couple of hosts that require much larger backups and other hosts that need to do very fast transfers, for example some VMs are hosted over NFS. For this reason I also use 10 Gbps Ethernet between the VM host and the network share. Hopefully soon I can get some trunked infiniband infrastructure deployed, but that’s a far future.
Archiving
- Host:
archive.hosakacorp.net - OS: Void Linux - Virtualized
In the last few months one of the hosts I’ve started using is an instance of ArchiveBox in order to download internet files that I like and want to search for later and additionally to facility my OSINT data harvesting on certain accounts. I call this out specifically because I consider this host to be “dangerous”. The software is a little sketchy at best and the deployment seems to do way more than I would normally like for an internet archive system. So I have taken extra precautions isolating and reducing access this specific host has on my network.
This host monitors and clones websites, blogs, RSS feeds, research papers, and social media accounts. My theory is that if it’s on the internet it’s not guaranteed to stay there. Keep copies. Keep evidence.
Additionally, this host uses Elasticsearch to store documents for quick searching. I have attempted to host the indexes on NFS for searching on different instances but, I haven’t fully fleshed out this build.
Virtual Host
- Host:
vhost.hosakacorp.net - OS: Void Linux - Physical
One of the more beefy systems on the network is my virtual host system, it’s a 24 Xeon core (2x CPU) and 24 ECC gigs of RAM. The host utilizes libvirt and not much else, following my simplicity principle. For the longest time I used raw QEMU, which worked great, but was hard to manage at scale and didn’t easily integrate with SELinux. Libvirt is definitely easier to deal with and manage. Here is what was currently running when I gave my devices a list:
$ ssh core@vhost virsh list --all
Id Name State
---------------------------
2 git running
3 intra running
4 notes running
14 ci-2 running
23 data running
24 archive running
- ca shut off
- ci shut off
- kali shut off
- dev shut off
- gw shut off
This virtual host also has a separate connection to the NAS using a 10Gbps Ethernet, which is occasionally used for specific virtual host disks and/or datasets.
Router & DNS
- Host:
ice.hosakacorp.net/firewall.hosakacorp.net/dns.hosakacorp.net - OS: OpenBSD - Physical
The core router and firewall in my network is using an awesome little piece of hardware, a PCEngines apu4d4. This serves multiple purposes in my network and the primary is being my internet gateway and core firewall. PF was the obvious reason I decided to use OpenBSD as it fits all my core needs and also now has core support for WireGuard in-kernel making it even more ideal.
This host also serves as my core DNS infrastructure since I run intranet only services. DNS is one of the few critical, but sketchy protocols. I have lots of experience doing DNS poisoning attacks in real world and I want to reduce some pain points. For that reason I do deploy a traditional unbound(8) DNS server, but the network also offers a DNSCrypt service internally. The unbound server forwards all requests through the upstream DNSCrypt server so that I can encrypt all DNS traffic from my ISP (I have a bad history with ISPs hijacking my DNS traffic… cough Comcast).
While unbound forwarding to DNSCrypt is good, I also want to protect hosts on my local LAN, so that same service is exposed on the host on a different port. I attempt to have all my hosts use DNSCrypt wherever possible.
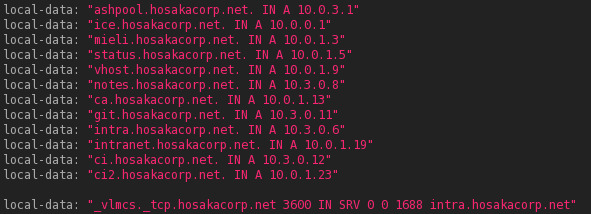
As for DNS management itself, I’m pretty old school. I manually enter my DNS entries for new hosts. A partial older example of these entries can be shown below, note how most are on the 10.3.0.0/16 subnet that I use for WireGuard:
Another important aspect to my network is my deep hatred of ads. It’s pretty common to see people suggest Pi-Holes or other solutions to this and in my opinion this is nonsense. Instead, I decided to take aggregated lists of adblock hosts and then directly convert them into manual unbound(8) configuration blocks and periodically reload the service. This can be seen in my very simple unad project.
Part of my process for blocking malicious hosts is also to enrich the DNS blocking information with blocklists from other sources using open and public known-bad lists and mixing them into my unad targets.
This also used to be my wireless access point, but OpenBSD had a hard time filling my performance needs for certain kinds of streaming, so I switched to OpenWRT based AP
Wireless Access Point
- Host:
ap.hosakacorp.net - OS: OpenWRT - Physical
In order to support some modern devices like a Chromecast and streaming HD video to my phone I had to compromise and switch my AP from a OpenBSD based host to a super minified OpenWRT AP on a TP-Link N900 that has no services running and only a management port accessible from a specific Ethernet connection. This host serves only to pass through to the normal network and isolate the hosts on the physical network from the wireless network. All wireless is hostapd all the way down.
ISP Modem
One of the biggest pain points in my network is the hellspawn of a device that is my ISP modem from AT&T. It’s trash. And it’s really untrustworthy. Luckily there is a commonly known way to trick the device into forwarding EAP packets in order to get access to AT&T network. Sadly this technique that uses eap_parrot and still requires the device to be online, so I haven’t been able to fully remove it. Though it only is plugged in and isolated from my internal network and has extremely strict firewall rules that essentially allow it to access nothing internet or intranet facing except EAP traffic.
I’ve been attempting to find a way around this, but that probably will be a post for another time (or not, don’t send C&Ds plz AT&T).
Workstation
- Host:
onosendai.hosakacorp.net - OS: OpenBSD - Physical
I love hand-me-down older laptops. I have been able to nab some older Lenovo X series devices over the year and my plan is to use them until they are run into the ground. Likewise, I use OpenBSD as my daily driver for all of my activities and anything that can’t work with that tends to get virtualized or put into CI. Following the principle of keeping things KISS I use dwm in a near default state. My days of heavily building and customizing my desktop environment are gone, so most of the changes I make are to my colors and a few keybinds.
I’ve also written a few “life improvement” things about using OpenBSD as your daily driver (and hopefully more), such as, using ifstated(8). I actually used to secretly do penetration testing and some Metasploit entirely from OpenBSD.
Cloud Systems & International Hosts
I keep a set of cloud systems and physical hosts in other countries that I use for various reasons. This website for example is a physical host in France. I use the other hosts for having static internet hosts without needing to expose my home network, backups, shared hosts, and for having multiple VPN ingress points when need be. One thing I like to do is keep my hosts available to use for direct VPNs whenever possible.
Misc. Devices
There are a couple of more devices in the network, but they aren’t important or interesting enough to make much more than a note of:
gaming/cracking- Dual boot Windows for gaming and then cracking when not gaming and sometimes gaming on the cracking OS (thanks PCI pass-through), but I don’t always want to fight anti-cheat engine checks for VMs.- Phone - It’s a phone, what do you want.
- reMarkable - One of my newer devices is my note-taking device, a reMarkable, which has a partial cloud sync back into my backup via a third-party Go binary that interfaces with the reMarkable cloud system.
- Chromecast - I will do anything to avoid getting a smart TV and the Chromecast comes with an Ethernet plug. It’s not my favorite, but VLC added support for Chromecast and allows me to use my NFS mount to cast and completely get around having to use something like Plex or Kodi. I’d love to get rid of this.
Configuration Management
Keeping this all in line can seem like a nightmare, but it really isn’t too hard to maintain. In order to automate many of the processes I attempt to start from square one with templates, even if things aren’t fully automated. That lets me integrate into whatever state management system I am using, or even just notes in a git repo.
I used to be a big proponent of Ansible and I still like it, but I find the model to be extremely restrictive and unusable on systems that either don’t have python or don’t fit into the Ansible model very well. For that reason I’ve recently become a big fan of pyinfra. I find the “in the end it’s all shell scripts or system calls” model very intriguing, and I prefer systems that are keeping state to provide me with a proper programming interface.
This also means that the network needs to keep a couple of things synchronized, such as my sudo and doas configuration. I’ve opted for the model that I learned from playing with Grsecurity’s exploit preventions, prefer DoS over compromise. Because of this I have a fairly uniform deployment of doas and sudo which lets me do most of my management.
permit nopass :sysadmins as root cmd syspatch
permit nopass :sysadmins as root cmd pkg_add args -u
permit nopass :sysadmins as root cmd fw_update
permit nopass :sysadmins as root cmd sysupgrade
permit nopass :sysadmins as root cmd reboot
Using this it becomes much easier to avoid having to fight sending credentials over state management. I’d rather someone reboot my servers and me get the syslog notification than have to pass sensitive credentials over any system.
Karesansui: The Zen
This portion of the article is just lamenting and thinking about how to best structure systems, it can be safely ignored if you are just here for technical content.
Technical spaces and groups are always interesting, one of the core reasons that I was always drawn to them and why I have so consistently participated is because of the passion that seems to drive everyone in the spaces. No matter the topic you will find someone who cares about any specific topic more than you ever thought could be possible. This drive and motivation was also what captured my attention and over the years the same passion and love for UNIX systems, cyber-security, and simplicity in technology. But I’ve made a terrible mistake. I accidentally turned my love and passion into zealotry and would often find myself trying to shake the person I’m having a discussion with into “seeing the light”.
This is wrong. On so many levels. About the time that I started noticing this was around the same time I was getting familiar with the term “blow-back”, which is a term used by intelligence agencies for having unforeseen negative impact from an operation. I had begun to notice that even approaching some people who were not already open-minded about the topic would just further solidify their opinion instead of changing it. Trying to evangelize to a group that already had an opinion very rarely bore fruit.
Instead of looking at the things I loved as tools I started to view them as a something to foster for myself. No longer was it about showing “the best way” but it was about cultivating a place that made me happy that I could continually improve on without anyone elses opinion. In Penetration Testing and OffSec in general many parts of my life revolve around the concept of tearing other peoples work apart and “breaking”. This little world I’ve created is the opposite. Instead of an ephemeral space where my work disappears at the end of an engagement, I am able to cultivate my own world that feels correct to me and can be improved upon.
So this document is going to serve as a living document of the opposition to the blow-back, this is the love letter to all the pieces of technology that fit just right in my brain and a way for me to write to myself. This way maybe I can show the world the amazing things and step-by-step show my place of Zen, a place that makes me happy and lets me build on the concepts that I love the most.
Models
Fundamentally when I break apart my world, typically things fall under a few simple mental models. Those models in the most abstract concepts are:
- Simplicity
- Composability
- Systems thinking
Most of these have been beaten into the ground and I don’t feel like I have much authority to talk on, but in general these are the guiding principles that I used to cultivate my little piece of cyberspace. In my experience as a pentester, the most frustrating and excruciating aspects often tie into the fact that people default to the shiny and new over the older solutions. One of the common pitfalls that I see is that people assume that the older historical “giants” have never thought about the problems that are being faced now by their new startup. The cloud fixed none of our problems, it just shifted them elsewhere to a deeper realm of technical debt that is harder to realize the implications of.
Systems Thinking
Systems thinking helps remove the focus on minutia and over-specialization. You aren’t building software the way that it’s specified, you are building something that is integrated into the greater whole. Hyper focus about spec or specific functionality often time neglects the holistic view. Systems are an ecological environment that involve both direct technical components, but also human and sociological components. It’s always critical to remember that the human is part of the system and components of a system include how people interact with them.
I view my system in the way that I interact with it and the way that it helps me exist in my environment. I am not worried about “I need git” I think, “how can I best track code in my world”. This framing has helped me easily build systems and allow my friends access in a way that makes it feel very much the same. Even these models are an aspect of that. I don’t choose the closest thing to spec or the hottest thing or the most featured system, I choose something based on how best it fits in the environment.
It’s not just about computers and operating systems, it’s about your environment.
Simplicity
Despite being the one that is most close to my heart, I believe that tons of more articulate people than myself have talk about the idea of “living a more simple life” and “simple software” to death. One of the things I will say on the topic, is that for me simplicity is something to strive for and is impossible to fully achieve, especially in a world with inescapable technical debt and human interactions.
Simplicity for me takes many forms and I think one of the most important aspects of it is understandability. I’m an okay programmer, but I find myself in the interesting cross-section of people who want to dig super deep but don’t want to make the super in depth details my work. Having simple to understand, but also highly technical pieces of code (or documentation for that matter) is a deliciously sweet spot. This is actually the reason that the suckless tools have always been so important to me, being able to just dive real quickly and modify the tooling to my liking without having any prior knowledge of the concepts is an incredibly powerful thing and directly interacts with other models described here.
I will always take fewer features and less impressive benchmarks for technology I can understand. Computers are magic that we understand and if we don’t understand it, it’s just magic.
OpenBSD
On the front of simplicity I believe that it’s important to comment on OpenBSD in my network.
Anyone who knows me knows that I love the security space and when they hear that I like OpenBSD they generally assume that it’s because of the security benefits. This is actually not the case, I actually strongly believe that Grsecurity and the HardenedBSD projects are probably “more secure” (whatever that means). The real reason I like OpenBSD is because of it’s tooling and developers philosophy.
Having the same people who develop the kernel and the userspace utilities has such an incredible impact of the user facing software experience that it’s hard to articulate. The Linux ecosystem is so fractured and the userspace utilities that are available for both commercial and open source usage vary so insanely that it becomes impossible to make really portable code without it breaking in some unexpected way. Not having that fractured userspace and kernel philosophy makes all the tooling far more consistent.
This is further shown in the documentation, which in my opinion is the second-best feature of OpenBSD. Literally everything I’ve ever needed has been documented, and in such a way that I have begun showing my developer friends how brilliant some of it is just to highlight what good documentation looks like. Just take a look at intro(1), each man page section has a layout and a description of the document sections. There is a reason OpenSSH is so popular beyond just being amazing code.
An additional thing I love is how the tooling respects administrators. Too often tooling is designed for “end-users” but the more you are a power user, the more sharp edges you find. It feels like OpenBSD writes and documents tools with reverence for sharp edges instead of hiding them.
Composability
Huge solutions that integrate every feature under the sun tend to be less useful to customize and build in a way that frees up the data and outputs. The more features there are the less likely it is able to be able to give you the outputs of something you are working on in a way that can be generically consumed.
Being able to take something in my network and be able to quickly tack it to something else allows me the most amount of flexibility. I can take my notes, integrate them into source code management, send them to a site generator to inject templates, generate LaTeX, HTML, and Gemini all from the same components and I don’t have to worry about which components have correctly created some integration feature.
In my opinion the only reason the “UNIX philosophy” meme has had the staying power is the simplicity of that composability. In penetration testing I constantly extract one format, convert it to another, enrich the data, and then generate statistics. Knowing how to think in a composable manner encourages analysis and integration in a way that isn’t obtuse. Adding Gemini support was as simple as integrating a build patchset, generating a format from markdown, and continuing on with my life. Roughly 30 lines-of-code let me turn my website into a full Gemini site because I followed composability wherever I could.